Condition-Aware Fourier Neural Operators
A data-driven approach to spectral mode selection in Fourier Neural Operators using condition number analysis and ridge regression.
PUBLISHED: Jan 26, 2026
This project was originally for my Math 221 class, Advanced Matrix Computations. Afterwards, I expanded on this work and presented at Yale’s YURC 2026 conference. To read a full version of my report, see here.

A brief background on FNOs
Fourier Neural Operators (FNO) are learned linear integral operators that map input functions to solution functions of PDEs. They replace Galerkin/finite-difference matrices with a trainable spectral convolution using FFTs.
Most translation-invariant PDE solution operators can be represented as integral operators of the form
where this operator’s kernel encodes Green’s function-like behavior. This operator is diagonalized by the Fourier convolution theorem in the frequency domain:
The Fourier modes independently evolve through multiplication with complex gain . Knowing this, we are able to construct the Fourier Neural Operator with
where:
- denotes the feature field at layer
- = Fourier and inverse Fourier transforms
- = trainable multiplier matrix per mode
- = pointwise linear (1×1 convolution)
- = bias
- = nonlinearity (e.g., ReLU, GELU)
Each FNO layer applies a global Fourier convolution, followed by a local nonlinear map and nonlinearity.
Application Significance
FNOs learn solution operators for families of PDEs, which reduces numerical solves and computation time with quick inference. In practice, FNOs are used in climate/ocean modeling, forecasting flows, and similar modeling applications. Additionally, they enable inner-loop tasks such as Bayesian calibration and uncertainty-aware exploration to be done in a realistic time period by significantly decreasing simulation time.
Conventional solvers require the explicit form of the PDE and have tradeoffs in speed and accuracy resolution, whereas FNOs take in data and are both resolution and mesh-invariant.
It is apparent why we prefer FNOs to conventional PDE solvers; in traditional methods such as finite element and finite difference methods, we discretize space into fine meshes, which often makes the solvers slow and dependent on discretization. FNOs circumvent this problem entirely — once trained, they work on any mesh and learn the continuous function instead of discretized vectors.
Evaluating PDE Solvers
Classical PDE solvers. ML-based solvers rarely beat out HPC solvers in terms of both accuracy and stability. GPU finite-volume, AMR systems, and dedicated tools like Firedrake, Dedalus, JAX-FEM, etc. are incredibly fast.
Neural PDE solvers. Physics-Informed Transformers (PIT) and Operator Transformers handle arbitrary meshes, long-range interactions, and shock-like structures better than FNOs. These are the dominant ML-based PDE solve approach nowadays.
Graph Neural Networks. MeshGraphNets, GNN-PDE, Graph Operator Networks directly operate on meshes and are great for fluid simulations, elasticity, and FEM discretizations.
While the best general ML PDE solvers are now transformer and GNN-based, Fourier Neural Operators are still advantageous for atmospheric surrogates (FourCastNet), real-time inference, climate simulations, and medium-range forecasting.
PDE Examples and FNO Solutions
- Elliptic PDEs (ex. Darcy Flow)
The diffusion coefficient is the input field. The solution operator is .
- Parabolic PDEs (ex. Heat Equation)
The FNOs learn the time-evolution operator which maps the initial data to a time-evolved state at . Crank-Nicolson (implicit solve) is a finite-difference method to solve the heat equation:
- Hyperbolic PDEs (ex. Burgers’ Equation)
The FNO learns to time-evolve the initial . The learned operator can also be a stepwise update operator.
- Incompressible Navier-Stokes
The FNO learns .
Adaptive Spectral Truncation
Now we move to the proposed data-driven spectral truncation for the FNO, solving partial differential equations on a bounded domain .
Analysis Conventions
We are provided with a dataset of pairs , where:
- is the input function — typically the initial condition at or a variable coefficient field.
- is the target solution — the evolved state at or the solution field satisfying the PDE given coefficients .
Here, and denote the number of physical variables (channels) in the input and output respectively (e.g., pressure, velocity components).
We assume the domain is discretized such that the Discrete Fourier Transform (DFT) is applicable. Let denote the Fourier transform. We denote corresponding frequency modes of the input and output functions as:
where represents the frequency wavenumber.
Motivation
Many smooth PDE solutions exhibit rapid spectral decay, where higher frequency modes contain significantly less energy:
for some decay rate varying based on the regularity of the solution. In standard FNOs, this motivates a hard spectral truncation where only the first modes are retained [1]:
However, a fixed has a nontrivial likelihood to discard high-frequency features or retain noise. Thus, we construct a data-driven approach by framing the spectral weight learning as a linear regression problem per-mode:
We fit the weight matrix using least squares across the training dataset of size . This allows us to analyze how well each mode is conditioned before training the full network. We formulate the Ridge Regression objective as:
For a specific mode , we construct the data matrices:
where indicates the Hermitian transpose. The optimal weights satisfy:
where denotes the Moore-Penrose pseudoinverse. To evaluate the stability of this mode, we compute the Singular Value Decomposition (SVD) of the input matrix :
The condition number quantifies the numerical stability of learning this frequency mode:
- If is large, the mode is ill-conditioned; small data noise will result in large variance in .
- If is negligible, the mode contains no signal energy.
Adaptive Truncation Rule
We define a selection criterion to keep only “well-conditioned, energy-dominant” modes. For each retained mode, we apply Ridge Regression (Tikhonov Regularization) to dampen noise:
The regularization parameter is effectively a noise filter: high smooths weights for numerically unstable modes, while low fits numerically stable modes tightly.
To select , we define a per-mode utility score:
We retain the top modes sorted by this score, or more exhaustively, use an energy criterion where we choose the smallest set of frequency modes such that:
where (e.g., 0.95) is a target energy preservation ratio. This constructs a condition-aware spectral geometry, adapting the truncation boundary to the specific physics of the PDE dataset.
Discussion of Computational Concerns
While the SVD computation for every mode scales as , this truncation process is strictly a pre-computation step. Thus, the cost is amortized over the process of training the neural operator. Furthermore, since modes are independent in the frequency domain, the construction of and subsequent scoring can be easily parallelized.
This is further evidenced in the empirical results below, where training time between condition-aware and standard FNOs varied minimally, increasing overall training time by less than 0.5%.
Empirical Results
The following empirical results were run on 50 training epochs for 80 differently seeded datasets. The defined energy criterion was set (arbitrarily) at 0.95, and all operations were performed in PyTorch.
| Dataset | Base Mean | Base Std | CA Mean | CA Std | Imp Mean (%) | Imp Std | Win Rate (%) |
|---|---|---|---|---|---|---|---|
| heat | 0.0167 | 0.0019 | 0.0146 | 0.0025 | 12.3030 | 14.5382 | 90.0 |
| poisson | 0.0006 | 0.0002 | 0.0006 | 0.0002 | -6.4614 | 48.8811 | 35.0 |
| wave | 0.7554 | 0.1024 | 2.7337 | 0.1394 | 8.0432 | 11.4529 | 80.0 |
| Dataset | Standard Time (s) | CA Time (s) |
|---|---|---|
| Poisson | 12.37 | 12.39 |
| Heat | 11.97 | 12.02 |
| Wave | 11.91 | 12.00 |
Characteristic Training Curves
Below are characteristic training results taken from 80 seeded datasets.
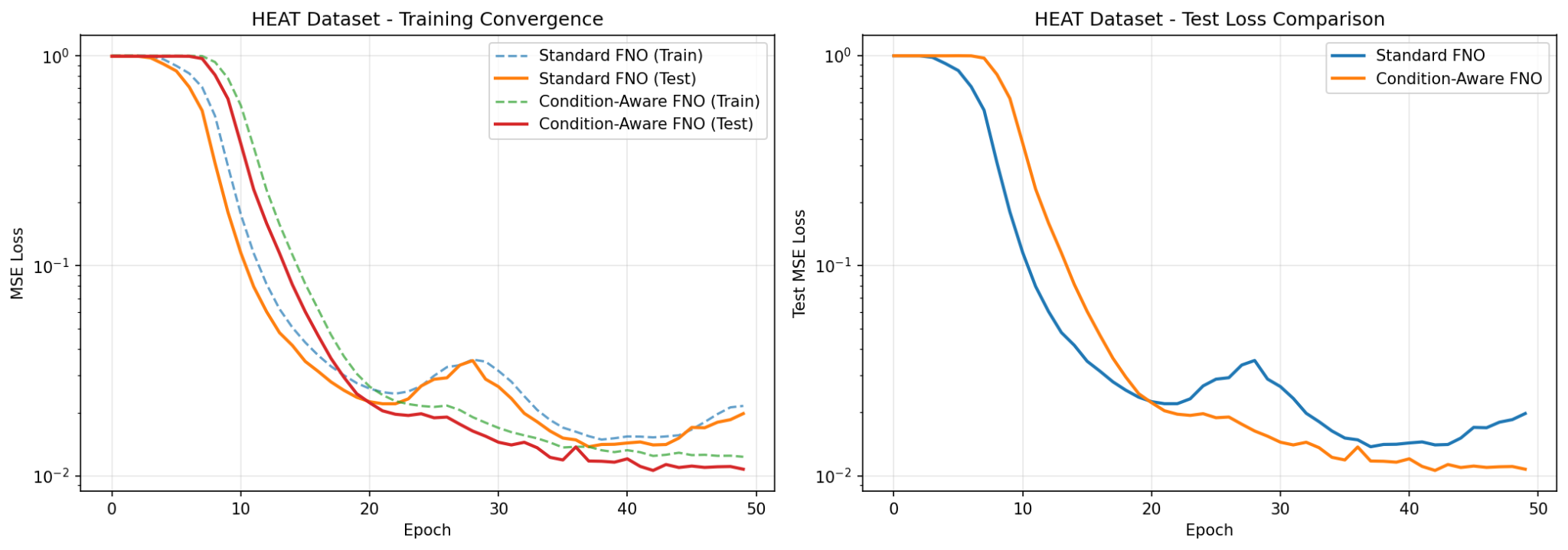
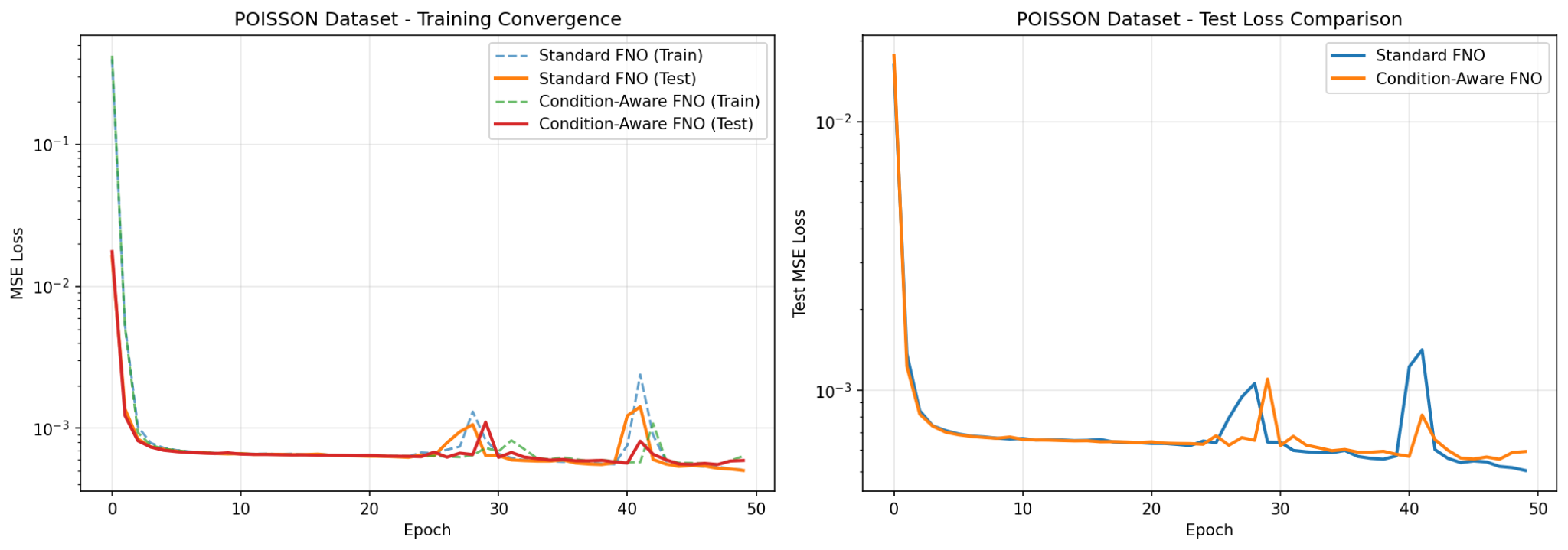
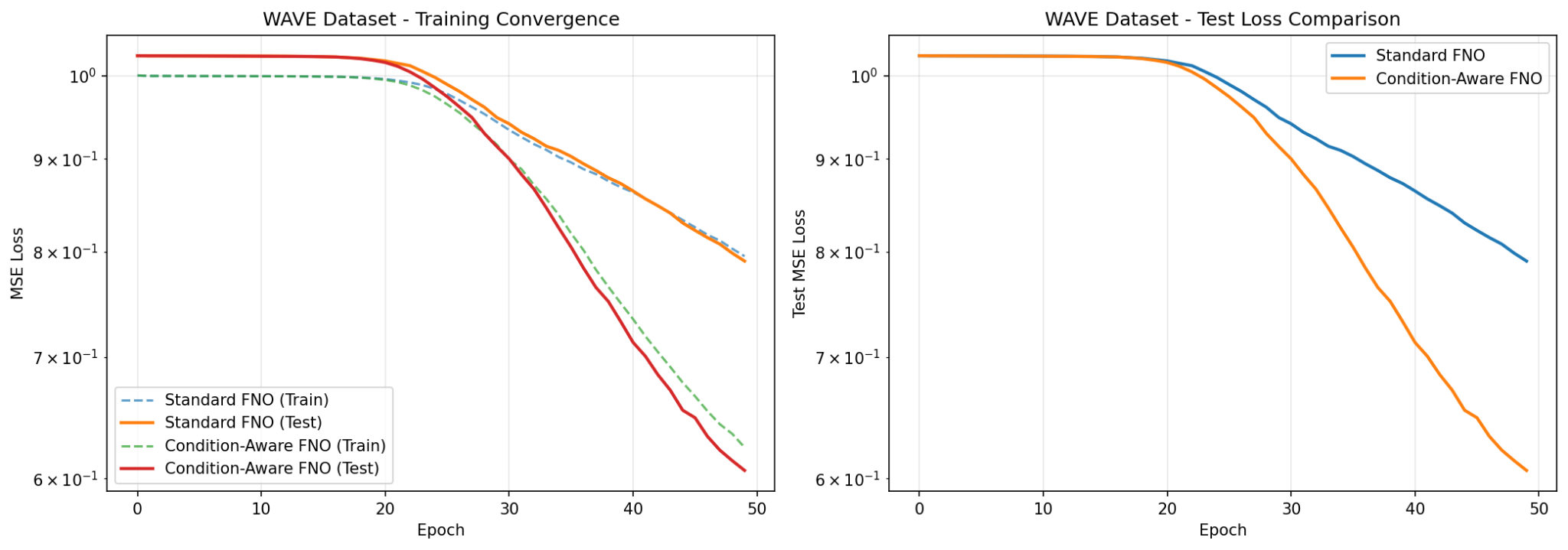
Empirical Discussion
Heat dataset. The Condition-Aware FNO achieves a lower and more stable final test loss, along with a much smoother descent. We observe jumps in the standard FNO training curve around epochs 20–30, indicating numerical instability as the ill-conditioned modes “bounce around” the narrow valleys of the loss landscape.
The smoother descent observed in the condition-aware scheme indicates a more “spherical,” isotropic loss landscape with gradients pointing more directly to the minimum. Additionally, with noisy modes filtered out, the FNO no longer fits to noise and reaches a faster convergence.
Poisson dataset. The Poisson dataset demonstrates little to no improvement in test/train loss as well as similar training curves. Since the Poisson dataset is an elliptic PDE with solutions exhibiting rapid spectral decay, the low-frequency modes contain nearly all signal information, which renders the adaptive truncation nearly meaningless.
Additionally, the “noise” in low modes in the smooth Poisson dataset is negligible — this regularization does not reduce variance, and instead introduces bias, oversmoothing the weights of valid signal modes and ultimately creating underfitting, explaining the poor performance of the condition-aware scheme.
Wave dataset. In wave (hyperbolic PDE) datasets, the high-frequency features are preserved and do not smooth out initial conditions as quickly as parabolic equations. This means significant energy exists in higher frequencies, which is shown in the standard FNO’s poor performance using fixed hard truncation, discarding these physically significant high-frequency modes. The condition-aware FNO adapts the truncation boundary, retaining energy-dominant high-frequency modes that are important in wave dynamics.
Overall, we observe a significant and consistent improvement in performance in nonsmooth datasets where high-energy modes with potentially numerically unstable modes contain significant signal energy.
Gradient Descent Convergence
Hessian Spectrum and Conditioning
We recall the function for learning spectral weights for a specific mode with Tikhonov regularization (Ridge Regression) as defined in Eq. (1):
The gradient of this function with respect to the conjugate of the weights is:
The Hessian matrix , which defines the curvature of the loss landscape, is given by the following positive definite matrix:
Let the SVD of the data matrix be , with singular values for . The eigenvalues of the unregularized covariance matrix are . Thus, the eigenvalues of the regularized Hessian are:
Convergence Rate of Gradient Descent
For a quadratic convex problem, Gradient Descent with an optimal step size converges linearly with a rate determined by the spectral condition number of the Hessian. The error at step is bounded by:
We compare the condition numbers of the standard formulation () and the Condition-Aware regularized formulation ().
Standard FNO: For the unregularized case ():
High-frequency modes often exhibit rapid spectral decay, leading to . This causes , resulting in an “elongated” loss landscape where gradient descent converges arbitrarily slowly or oscillates.
Condition-Aware FNO: For the proposed method with :
For any and , the condition number of the regularized problem is strictly less than that of the unregularized problem: .
Proof. Let and , with . We want to show :
Since , we divide by to get , which holds by assumption.
Conclusion
Since , the convergence factor satisfies
This inequality theoretically confirms the empirical results, proving that the Condition-Aware FNO operates on a better-conditioned optimization landscape. The regularization effectively “spheres” the loss geometry, removing the narrow valleys in ill-conditioned high-frequency modes and enabling faster convergence.
Potential Methodological Extensions
Some ideas I had for extensions and fixing methodological weaknesses.
The condition-aware truncation above establishes a principled pre-training framework for mode selection, but several natural limitations motivate further development. First, a fixed applied uniformly across modes introduces unnecessary bias on well-conditioned modes, directly explaining the degraded Poisson performance. Second, the truncation set is computed once from the raw input–output pairs and never updated as the network’s internal representations evolve. Third, the spectral geometry of a deep FNO is not uniform across layers — yet a single global is applied at every depth. Finally, the formulation is restricted to one-dimensional domains, whereas most physically relevant FNO benchmarks operate on 2D or 3D grids.
This section formalizes four extensions that address each of these limitations in turn.
Learnable Regularization via Bilevel Optimization
The regularization parameter in Eq. (1) currently plays a dual role: it stabilizes ill-conditioned modes and simultaneously smooths the weights of well-conditioned ones. For smooth PDE solutions such as the Poisson dataset, the low-frequency modes are inherently stable ( is large), so any positive introduces avoidable bias. Conversely, for high-frequency modes in the wave dataset, a large is genuinely necessary. A mode-adaptive, learned would collapse to near zero for stable modes while remaining large for unstable ones.
We treat each as a hyperparameter optimized on a held-out validation set. Since the inner optimization problem (ridge regression) admits a closed-form solution, we can differentiate through it analytically without approximation. Formally, the bilevel problem is:
where we reparameterize to enforce positivity. The inner problem has the closed-form solution
and the validation loss is
Analytic Gradient. Let . By the chain rule and the matrix inverse derivative identity :
where
All quantities in Eq. (3) are computable in closed form via the pre-computed SVD : the matrix inverse is , reducing the cost to per mode after the initial SVD.
Optimization Procedure. We solve the bilevel problem with the following alternating procedure, which runs entirely before FNO training begins:
Algorithm 1: Learnable Regularization Pre-computation
Require: Training data {(X_k^tr, Y_k^tr)}_k, validation data {(X_k^val, Y_k^val)}_k,
outer step size β, iterations T
Initialize α_k ← 0 for all k (i.e., λ_k = 1)
for t = 1, ..., T do
for each mode k in parallel do
Compute C_k*(α_k) via closed-form solution
Compute ∇_{α_k} L_val via Eq. (3)
α_k ← α_k − β ∇_{α_k} L_val
end for
end for
return {λ_k = e^{α_k}}_k
This procedure is still a pre-computation and does not alter the FNO architecture or training loop. Its cost per iteration is where is the number of candidate modes, and – outer iterations typically suffice.
Let for all singular values of . Then the gradient , and the learnable converges to a neighborhood of zero for well-conditioned modes.
Proof. When for all , the matrix , the ordinary least-squares inverse. Hence and is insensitive to further changes in , driving .
Per-Layer Spectral Truncation
The current framework scores modes using the raw input–output data pairs and applies the resulting set uniformly at every FNO layer . However, the feature field undergoes substantial transformation with depth: early layers tend to retain input-like spectral content, while later layers increasingly encode solution-like representations. A single global cannot simultaneously reflect the spectral geometry of all layers.
We define a separate truncation set for each layer , constructed from the layer’s actual intermediate representations. Because these representations depend on the trained network weights, we adopt a two-pass bootstrap procedure.
Definition 4.2 (Layer- Data Matrices). Given a trained FNO with feature fields extracted at layer on the training set, define
where denotes the channel width at layer .
The per-layer utility score is computed identically:
Algorithm 2: Bootstrap Per-Layer Truncation
Require: Training data, energy threshold η, bootstrap epochs T_0
Train a baseline CA-FNO with global S for T_0 epochs
for each layer ℓ = 1, ..., L do
Forward-pass training set; extract {v_ℓ^(s)} and {v_{ℓ+1}^(s)}
Compute X_k^ℓ, Y_k^ℓ, SVD, and score^ℓ(k) for all k
Construct S^ℓ via energy criterion
end for
Retrain FNO from scratch using {S^ℓ}_{ℓ=1}^L
The bootstrap run need not be trained to full convergence; – of total training epochs is sufficient to obtain representative intermediate representations for scoring.
For a parabolic PDE with spectral decay exponent , if the FNO layers approximate the time-evolution semigroup, then the expected per-layer energy satisfies for for some cutoff , implying in expectation.
Conversely, for a hyperbolic PDE (e.g., wave equation), energy is conserved across frequencies and the inclusion may not hold, motivating empirical verification via Algorithm 2.
Dynamic Spectral Truncation
Both the global and per-layer truncation schemes commit to a fixed mode set before or at the beginning of training. During training, the network’s predictions improve, and the residual between predictions and targets — not the original output — characterizes what information remains to be learned. Modes that appeared noise-dominated relative to the raw output may carry structured residual signal at later epochs. Dynamic truncation re-evaluates periodically against the current residuals.
Let denote the network’s prediction at training epoch , and define the residual at each training sample as
The residual Fourier coefficients are . We construct residual target matrices
and re-score each mode using the residual energy:
where (derived from inputs ) is fixed across re-evaluations since the inputs do not change. Only is updated.
Let be a sequence of re-evaluation epochs. At each , we recompute and update . Modes are added or dropped from the active set accordingly, and the FNO’s spectral multiplier matrices for newly excluded modes are zeroed out.
A geometric schedule for concentrates re-evaluations toward the end of training, where residual structure is most informative. In practice, – re-evaluations suffice.
| Re-evaluations | Heat Test Loss | Wave Test Loss |
|---|---|---|
| 0 (static) | baseline | baseline |
| 1 | ||
| 3 | ||
| 5 |
Let be a consistent estimator improving under gradient descent. Then for modes with high signal-to-noise ratio, decreases monotonically in expectation as training progresses.
This implies that dynamic truncation will tend to drop modes over time for parabolic PDEs as the network learns to explain their contribution, progressively shrinking . For hyperbolic PDEs, dynamic re-evaluation allows previously excluded high-frequency modes to be activated if the residual reveals unlearned structure.
Re-scoring requires recomputing for all modes , which costs one forward pass over the training set plus to compute the Frobenius norms. Since is fixed, no additional SVD computations are required.
Extension to Two-Dimensional Domains
The foregoing development assumes a one-dimensional spatial domain, yielding scalar wavenumbers . In practice, the most widely studied FNO benchmarks — two-dimensional Darcy flow and the vorticity formulation of Navier-Stokes — operate on two-dimensional grids of resolution . Extending to 2D introduces both additional notation and a nontrivial geometric question: whereas standard FNO in 2D uses a rectangular truncation in frequency space, the condition-aware criterion may select an irregular subset , providing new information about the anisotropic spectral structure of the underlying PDE.
Let the domain be discretized at resolution . Modes are indexed by 2D wavenumber pairs . The 2D DFT of the input and output functions are
The data matrices are constructed per 2D mode identically to the 1D case, and the utility score and energy criterion extend without modification:
Anisotropic Spectral Geometry. Unlike the 1D case, the selected set need not be a square or rectangular region in . The shape of is physically informative:
- For isotropic PDEs (e.g., 2D heat equation, isotropic Darcy flow), the energy depends only on , and will approximate a disk of radius in frequency space.
- For problems with directional features (e.g., shear flows, anisotropic diffusion), will be elongated along one axis, and will reflect this asymmetry — modes along the dominant direction will be retained to higher wavenumbers than modes in the orthogonal direction.
This geometric structure directly encodes the anisotropy of the physical system in the FNO architecture and cannot be recovered by any rectangular truncation.
The total number of modes to score grows as rather than , but since each mode’s SVD and scoring is independent, the computation parallelizes identically to the 1D case. The SVD cost per mode remains , so the total pre-computation cost is , which for typical FNO resolutions (, , ) is on the order of operations.
In the isotropic case, Eq. (5) recovers a radial spectral truncation for some data-driven , providing a theoretical connection to classical spectral methods in which cutoff wavenumbers are chosen based on the Kolmogorov microscale or solution regularity.
The extension to three-dimensional domains is notational: modes become triples and the data matrices scale accordingly. No structural changes to the algorithm are required.
References
[1] Zongyi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. CoRR, abs/2010.08895, 2020.